
论文阅读:NAGphormer
Metadata
- 作者: Jinsong Chen, Kaiyuan Gao, Gaichao Li, Kun He
- 日期: 2023
- 出处: ICLR
- 开源代码: https://github.com/JHL-HUST/NAGphormer
- PDF: https://arxiv.org/abs/2206.04910
研究问题
根据论文内容,本文的核心研究问题可概括为以下两点:
- 现有图Transformer的可扩展性瓶颈问题
当前主流图Transformer(如GT、Graphormer等)在处理图数据时,将所有节点视为独立token并组合成单一长序列进行训练,导致自注意力机制的计算复杂度高达 $O(n²)$($n$ 为节点数)。这使模型无法扩展到大规模图数据(如百万级节点),因为:(1)GPU内存无法承载全图训练;(2)传统GNN的优化策略(如节点采样、近似传播)不适用于全局注意力的Transformer架构。 - 邻域信息利用效率不足
GNN常因过平滑(over-smoothing)和过挤压(over-squashing)问题难以有效捕获深层邻域信息。而解耦GCN(如GPRGNN)虽通过固定权重聚合多跳邻域,但无法动态学习不同跳数的重要性。现有图Transformer虽引入图结构编码,却未充分考虑局部邻域的语义关联性。
创新方法
基于论文内容,本文提出的核心创新方法是 NAGphormer(Neighborhood Aggregation Graph Transformer),其核心是 Hop2Token 模块和 基于注意力的读出机制,用于解决传统图 Transformer 在大规模图上面临的复杂度过高和无法批量训练的问题。具体创新点如下:
1. Hop2Token 模块
- 核心思想:传统图 Transformer 将每个节点视为独立 token 组成长序列,导致自注意力计算复杂度为 $O(n^2)$,难以扩展到大图。Hop2Token 将每个节点自身视为一个独立的序列(Sqeuence)。
- 数学表示:对于节点 $v$,其 $k$ 跳邻居 $\mathcal{N}^k(v)$ 的信息被聚合成一个令牌(Token) $x_v^k$:
- 序列构建:为节点 $v$ 构造一个包含从 $0$ 跳(自身)到 $K$ 跳邻居聚合特征的令牌序列:
- 高效实现(关键创新):
- 使用归一化邻接矩阵 $\hat{A}$ 的幂次进行高效传播,计算 $k$ 跳邻居矩阵:
- 此步骤可离线预处理,将所有节点的序列 $S_v$ 存储在张量 $X_G \in \mathbb{R}^{n\times (K+1) \times d}$ 中。
- 优势:
- 支持批量训练:每个节点序列独立,可在 GPU 上以小批量方式训练 Transformer,使模型能处理任意大小图数据 (Chen等, 2023) 。
- 显式保留跳数信息:保留了不同跳数邻居的语义关联信息,这是普通 GNN 所忽视的。
2. NAGphomer 模型架构
模型流程如图 1 所示 (Chen等, 2023) :
- 结构编码:融合节点原始特征 $X$ 和图拉普拉斯特征向量 $U$(捕捉结构信息):
- Hop2Token:使用预处理得到的 $X’$ 构建节点序列张量 $X_G$。
- 线性投影:将序列映射到 Transformer 的隐藏维度:
- Transformer 编码器:将投影后的序列 $Z_v^{(0)}$ 输入标准 Transformer 层(多头自注意力 MSA + FFN)学习表示:
- 注意力读出机制 (Innovative Readout):
- 动机:不同跳数邻居对节点表示的贡献不同。
- 公式:计算 $k$-hop token 相对于 $0$-hop (节点自身) token $Z_0$ 的注意力权重 $\alpha_k$,加权聚合:
- 此机制自适应学习不同跳邻居的重要性,是性能提升的关键。
3. 理论分析贡献
- 作者论证了 NAGphomer 相比流行的 解耦 GCN (Decoupled GCN)(如 GPRGNN, APPNP)的优势:
- 解耦 GCN 可视为使用固定且稀疏的注意力矩阵(仅最后一行 $\beta_k$ 非零)(Fact 1, Appendix C) (Chen等, 2023) 。
- NAGphomer 则通过 Transformer 的自注意力机制显式建模不同跳 token 之间的语义关联,再通过注意力读出机制自适应融合,因此能学习到更具信息量的节点表示。
总结:NAGphormer 的创新核心在于 Hop2Token 模块(将节点转化为其多跳邻居聚合的令牌序列,公式 (5)(6))和注意力读出机制(公式 (11)(12)),使图 Transformer 能在保持强表达能力的同时,通过批量训练高效处理大规模图,并在节点分类任务上超越传统图 Transformer 和主流 GNN。
模型架构
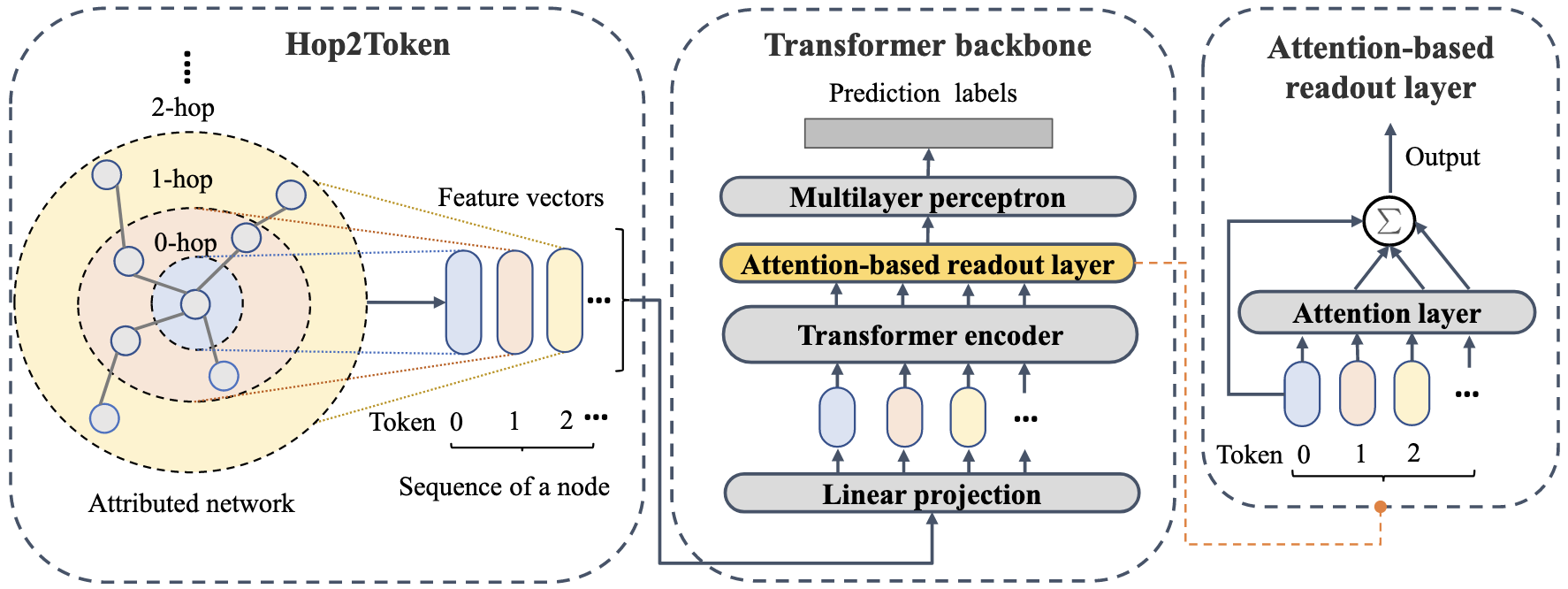
模型核心架构:NAGphormer
NAGphormer(Neighborhood Aggregation Graph Transformer)是一种面向大规模图节点分类任务的创新型图Transformer模型。其核心创新在于通过Hop2Token模块将图结构转化为序列数据,解决了传统图Transformer因全局注意力机制导致的二次计算复杂度问题,使其能够高效处理百万级节点的大规模图(如Amazon2M)。模型架构如图1所示(基于论文描述绘制的示意图):
graph LR
A[Attributed Network] --> B[Hop2Token模块]
B --> C[Linear Projection<br>特征投影]
C --> D[Transformer Encoder<br>多层自注意力]
D --> E[Attention-based Readout<br>自适应聚合]
E --> F[MLP Classifier<br>标签预测]
关键组件详解
- Hop2Token模块(核心创新)
- 功能:为每个节点生成一个token序列,序列中每个token表示该节点某一跳邻居的聚合特征。
- 第0跳:节点自身特征 $x_v^0 = φ({v})$
- 第k跳:k-hop邻居聚合特征 $x_v^k = φ(𝒩^k(v))$
- 实现方式:通过邻接矩阵的幂运算高效计算(算法1):
- 输出:每个节点对应一个长度为(K+1)的token序列 $S_v = [x_v^0, x_v^1, \ldots, x_v^K]$。
- 功能:为每个节点生成一个token序列,序列中每个token表示该节点某一跳邻居的聚合特征。
- 结构编码(Structural Encoding)
- 拼接拉普拉斯特征向量(图结构信息)到原始节点特征:以增强模型对拓扑结构的感知能力。
- Transformer编码器
- 将Hop2Token输出的序列通过线性投影映射到隐藏维度:
- 使用多层Transformer块(含MSA和FFN)学习token间语义关联。
- 注意力读出层(Attention-based Readout)
- 功能:自适应融合不同跳邻居的重要性:
- 通过注意力机制区分不同跳数对目标节点的贡献差异。
- MLP分类器
- 最终节点表示 $Z_{out}$ 输入多层感知机预测节点标签。
创新优势
- 可扩展性:通过节点级序列化设计,支持小批量训练(时间复杂度 $O(n(K+1)^2d)$),显著降低计算开销(如Amazon2M上训练时间58.6秒/epoch)。
- 表达能力:理论证明(Fact 1)表明,相比解耦GCN的固定权重聚合,NAGphormer的自注意力机制能学习更丰富的多跳邻居表示。
- 效果领先:在9个数据集(含3个百万级图)上超越所有对比模型,最高提升2.32%(Physics数据集)。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 EpsilonZ's Blog!
相关推荐
2026-03-17
论文阅读:HDSE
Enhancing Graph Transformers with Hierarchical Distance Structural Encoding
2026-03-17
论文阅读:NTFormer
NTFormer:A Composite Node Tokenized Graph Transformer for Node Classification
2026-03-17
论文阅读:Simple Path Structural Encoding
Simple Path Structural Encoding for Graph Transformers
2026-03-17
论文阅读:Vcr-Graphormer
Vcr-graphormer:A mini-batch graph transformer via virtual connections
2026-03-17
论文阅读:DUALFormer
DUALFormer:Dual Graph Transformer
2026-03-17
论文阅读:Primphormer
Primphormer:Efficient Graph Transformers with Primal Representations

