论文阅读:NTFormer
Metadata
- 作者: Jinsong Chen, Siyu Jiang, Kun He
- 出处: IEEE Transactions on Big Data
- PDF: http://arxiv.org/abs/2406.19249
摘要
摘要—近年来,新兴的图Transformer在图节点分类任务上取得了显著进展。在大多数图Transformer中,一个关键步骤是将输入图转换为令牌序列(token sequences)作为模型输入,使Transformer能够有效学习节点表示。然而,我们观察到现有方法仅通过单类型令牌生成表达节点的部分图信息。因此,它们需要定制化的策略将额外的图特定特征编码到Transformer中,以确保节点表示学习的质量,这限制了模型处理多样化图的灵活性。为此,我们提出了一种新的图Transformer称为NTFormer来解决这个问题。NTFormer引入了一种新颖的令牌生成器Node2Par,它使用不同的令牌元素为每个节点构建各种令牌序列。这种灵活性使Node2Par能够从不同角度生成有价值的令牌序列,确保丰富图特征的全面表达。受益于Node2Par的优势,NTFormer仅利用基于Transformer的主干结构,无需图特定修改即可学习节点表示,消除了对图特定修改的需求。在包含不同规模同配性和异配性图的多种基准数据集上进行的大量实验证明,NTFormer在节点分类任务上优于代表性的图Transformer和图神经网络。
研究问题
本论文主要研究的问题是图神经网络中节点分类任务面临的token序列构建不全面的问题。具体来说,当前大多数图Transformer方法在将输入图转换为token序列作为模型输入时,仅使用单类型token生成来表达节点的部分图信息,这导致了以下局限性:
- 信息表达不完整:现有方法只能表达节点的部分图信息,无法全面捕捉复杂的图特征。
- 需要额外定制策略:为弥补上述不足,这些方法需要设计特定策略将额外图特征编码到Transformer架构中,以确保节点表示学习的质量。
- 模型灵活性受限:这些定制化的处理方式限制了模型处理多样化图结构的能力,无法灵活适应不同类型的图数据。
从论文摘要和引言可以看出,作者观察到”现有方法仅通过单类型token生成表达节点的部分图信息”,因此研究目标是通过设计更全面的token生成机制,使模型能够自然地表达丰富的图特征,而无需依赖特定的图结构修改或额外的编码策略。
作者提出的解决方案是NTFormer模型,该模型引入了名为Node2Par的新token生成器,能够为每个节点构建多种token序列,从不同角度表达图特征,从而解决了传统方法中的局限性问题。
方法
NTFormer方法详解
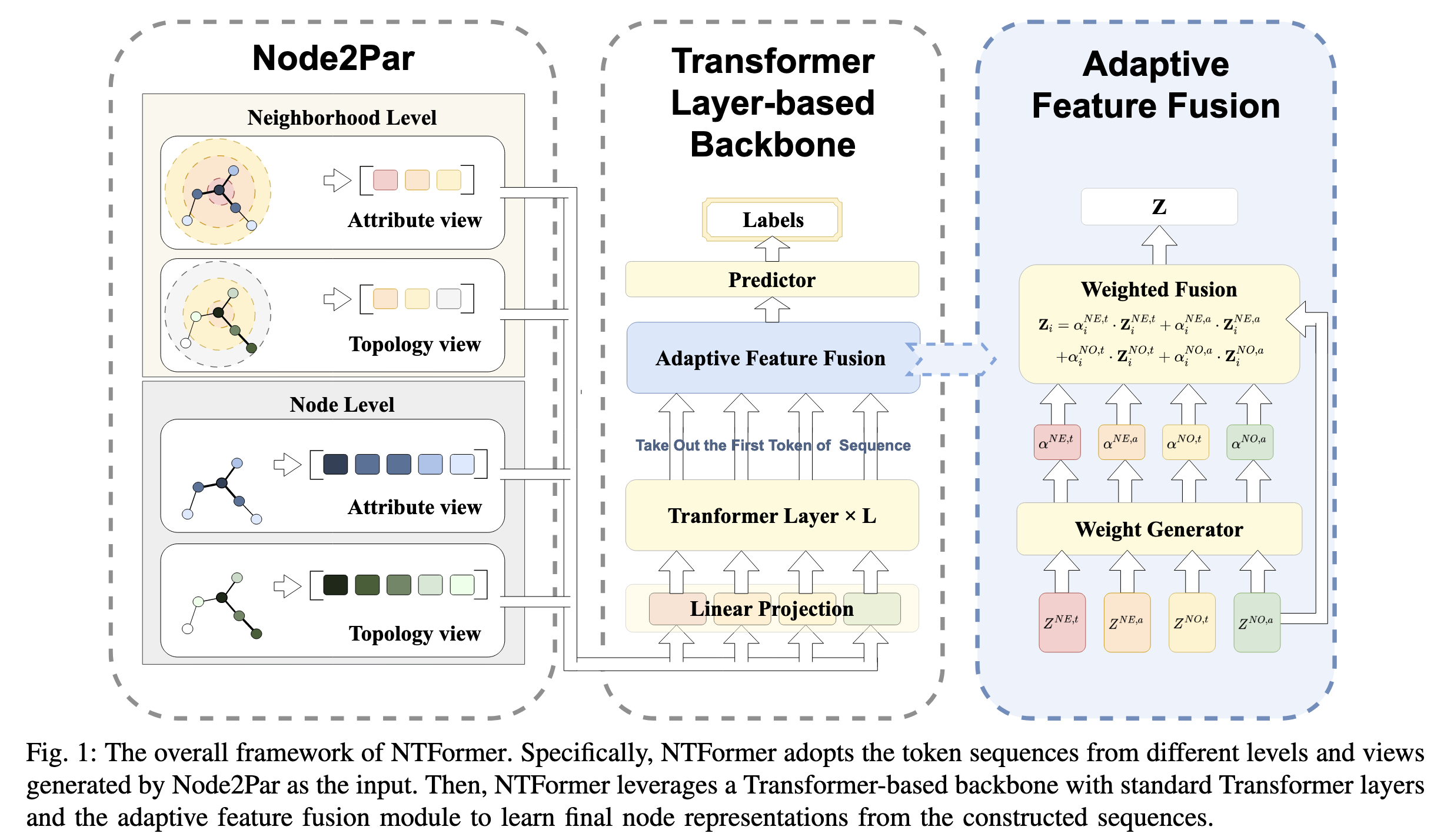
一、Node2Par标记序列生成器
Node2Par是一个创新的标记序列生成器,从拓扑和属性两个视图为每个节点构建两种类型的标记序列:邻域标记序列和节点标记序列。
1.1 邻域标记生成器
邻域是描述目标节点周围连接的重要元素。作者首先提出邻域特征聚合的通用形式:
其中:
- 表示节点的跳邻域
- 表示节点在邻域中的聚合权重
- 表示节点的属性特征
- 表示节点本身视为跳邻域
为全面表达邻域信息,作者从拓扑和属性两个视图构建邻域标记:
对应的权重计算为:
其中:
- 是带自环的归一化邻接矩阵
- 是通过余弦相似度()计算的属性相似性矩阵
- 是邻接矩阵
- 表示元素级乘积(哈达玛积)
最终生成两种邻域标记序列:拓扑视图和属性视图。
1.2 节点标记生成器
为解决邻域标记在捕获节点级信息(如长距离依赖)方面的局限,作者引入节点标记生成器,采用两步策略:
- 测量节点相似度分数
- 选择最相似的节点构建标记序列
其中:
- 是所有节点对的评分矩阵
- 选择具有最高相似度分数的个节点
作者从两个视图计算评分矩阵:
拓扑视图():采用个性化PageRank(PPR)方法
其中:
- 表示第次传播步骤的PageRank分数
- (的第列)
- 是阻尼常数因子
- 是个性化one-hot向量
属性视图():直接应用余弦相似度计算节点属性相似性。
二、基于Transformer层的主干网络
获得四个标记序列()后,作者提出Transformer主干网络。
2.1 Transformer层输入投影
以邻域标记为例,首先进行特征投影:
其中是投影矩阵。
2.2 Transformer层处理
应用标准Transformer层学习节点表示:
其中是多头自注意力机制,是前馈网络。从输出中提取第一行作为节点表示。
同理获得其他表示。
2.3 自适应特征融合
提出自适应融合模块获取最终节点表示,首先计算各特征的融合权重:
其中:
- 和是可学习参数矩阵
- 是激活函数对各权重进行归一化后,加权融合得到最终表示:
2.4 预测器与损失函数
节点分类任务使用MLP预测标签并采用交叉熵损失:
其中是已知标签节点的集合。
三、方法创新点与优势
- 多视图标记生成:Node2Par从拓扑和属性两个视图分别生成邻域级和节点级标记序列,全面表达图信息,解决了先前方法仅使用单一类型标记的局限性。
- 无需图特定修改:得益于Node2Par提供的丰富信息,NTFormer仅需标准Transformer层即可学习节点表示,无需特定的位置编码或注意力偏向,增强了模型处理不同类型图的灵活性。
- 自适应特征融合:通过学习自适应权重融合不同类型的标记序列表示,使模型能够根据图的特性(同配性/异配性)灵活调整不同标记的贡献度。
实验表明,NTFormer在各种规模的基准数据集上均优于代表性图神经网络和图Transformer方法,特别在异配图上表现突出,验证了其有效性和通用性。
附录
1.PPR计算方法详解
在NTFormer论文中,PPR(Personalized PageRank)用于计算节点之间的相似度矩阵以生成基于拓扑的节点标记序列。PPR计算的具体方法在论文的IV.B节”Node-based Token Generator”中有详细描述。可以对比VCR-Graphormer进行理解。
PPR计算公式
论文中给出的PPR计算公式如下:
其中:
- 表示从目标节点在第次传播步骤的所有节点的PPR分数
- 表示初始状态
- 是阻尼常数因子
- 是one-hot个性化向量,其中目标节点对应的元素等于1,其他为0
计算步骤
- 初始化:对于目标节点,创建一个one-hot向量,其中目标节点对应的元素为1,其他为0。
- 迭代计算:使用给定公式进行l次迭代计算PPR分数。每次迭代都考虑当前分数与阻尼因子。
- 实际实现:根据论文描述,在实践中采用了两步传播来估计节点的PPR分数,即进行两次迭代计算。
- 构建相似度矩阵:最终,所有节点对某个目标节点的PPR分数构成相似度矩阵。
拓扑矩阵Â
公式中使用的是归一化的邻接矩阵加上自环,定义为:
其中:
- A 是原始邻接矩阵
- D 是对角度矩阵
- I 是单位矩阵
这种归一化处理使得PPR计算能够考虑节点的度数信息,更好地反映节点在图中的重要性。
通过这种方法,NTFormer能够量化节点间的拓扑关系,为后续生成拓扑视图的节点标记序列提供基础。
References