图神经网络简介 | An Introduction to GNN
图的表示
对于图,有
- V:Vertex(or node) attributes
- E:Edge(or link) attributes and directions
- U:Global(or master node) attributes
分别可以使用向量embedding来进行表示。
图片转化为图
将第$(i, j)$位置的像素映射为第$(i, j)$位置的节点(可以将节点按照类似像素排序的规则排序,即每行每列个数均固定。对于图采用邻接矩阵进行存储。对于某个像素的邻居,为上下左右和对角线上至多8个节点,进而表示为图
文本转化为图
可以将每一个词表示为一个顶点,上一个词和下一个词之间有一个有向的边。
其它问题转化为图
分子转化为图
可以使每个原子表示一个节点,原子之间有边相连则表示一条边。
社交网络图
如同一场景中出现过的人,可以将其对应的节点连一条边。
引用图
如文章A引用文章B,则可以连接A指向B的有向边。
图机器学习的任务
- 图层面的任务,如识别有几个环进而对图进行分类
- 顶点层面的任务,如对两个复杂的社交网络图,对其中以两个人为核心的两个不同阵营,判断每个人属于哪个阵营
- 边层面的任务,预测边的属性
机器学习用于图上的挑战
(此处机器学习特指神经网络)
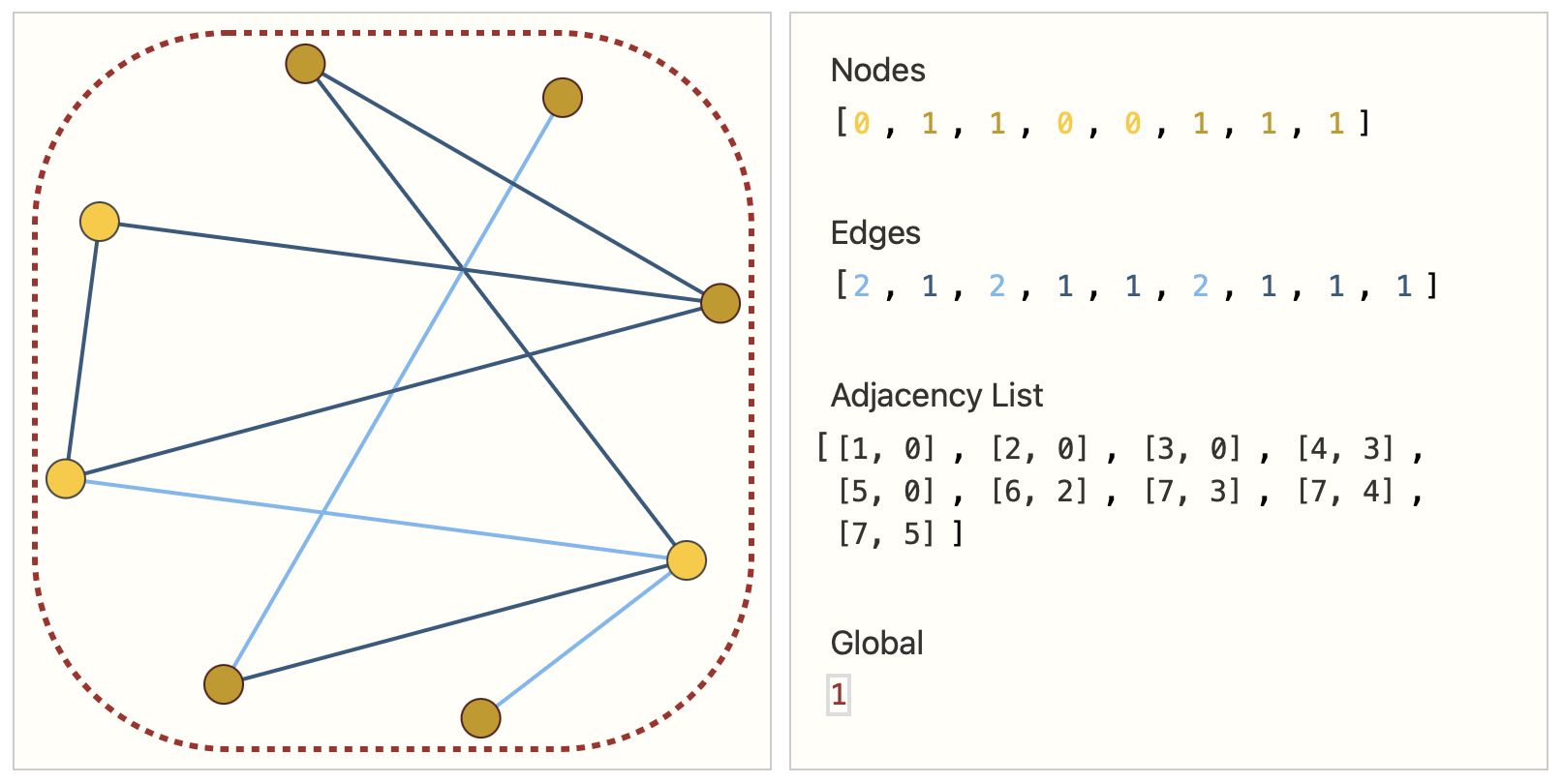
图上有四种信息:顶点的属性、边的属性、全局信息和连接性。前三种均可用向量表示,但连接性表示比较困难。
一种朴素想法是使用邻接矩阵,连接则用1表示,未连接用0表示。但是这种方法表示的矩阵会非常大。如果使用稀疏矩阵,在存储上可行,但要高效计算或者在GPU上计算较为困难。此外,由于交换任意行和任意列不会产生影响,这意味着交换任意行或任意列后的图放进神经网络,出来的结果应该与原先相同。
因此我们可以采用如下的形式。使用一个向量来表示节点,每个节点的属性使用一个标量来表示;用一个向量来表示边,每个边的属性也使用一个标量来表示;使用邻接链表来表示连接性。如下图所示:
图神经网络
图神经网络是对图上所有的属性,包括顶点、边、上下文等,进行一个可以优化的变换,而这个变换可以保持住图的对称信息(顶点重新排序后结果不变)。此处采用信息传递的神经网络。图神经网络输入为图,输出也是图,对图的顶点、边和全局上下文进行变换,但不对连接性产生改变。
最简单的GNN
使用上文所提出的数据结构,对全局上下问信息、顶点和边分别建立多层感知机,从而获得一个新的图。
GNN Predictions by Pooling Information
若没有顶点点向量,则使用汇聚/池化(Pooling)来得到节点向量。将与该节点的边的向量和全局向量一起相加得到新的向量(此处假设全局向量和边的向量维度相同,如果不同则需要进行投影),得到的新的向量作为节点的向量。最后进入全连接层得到顶点的输出。
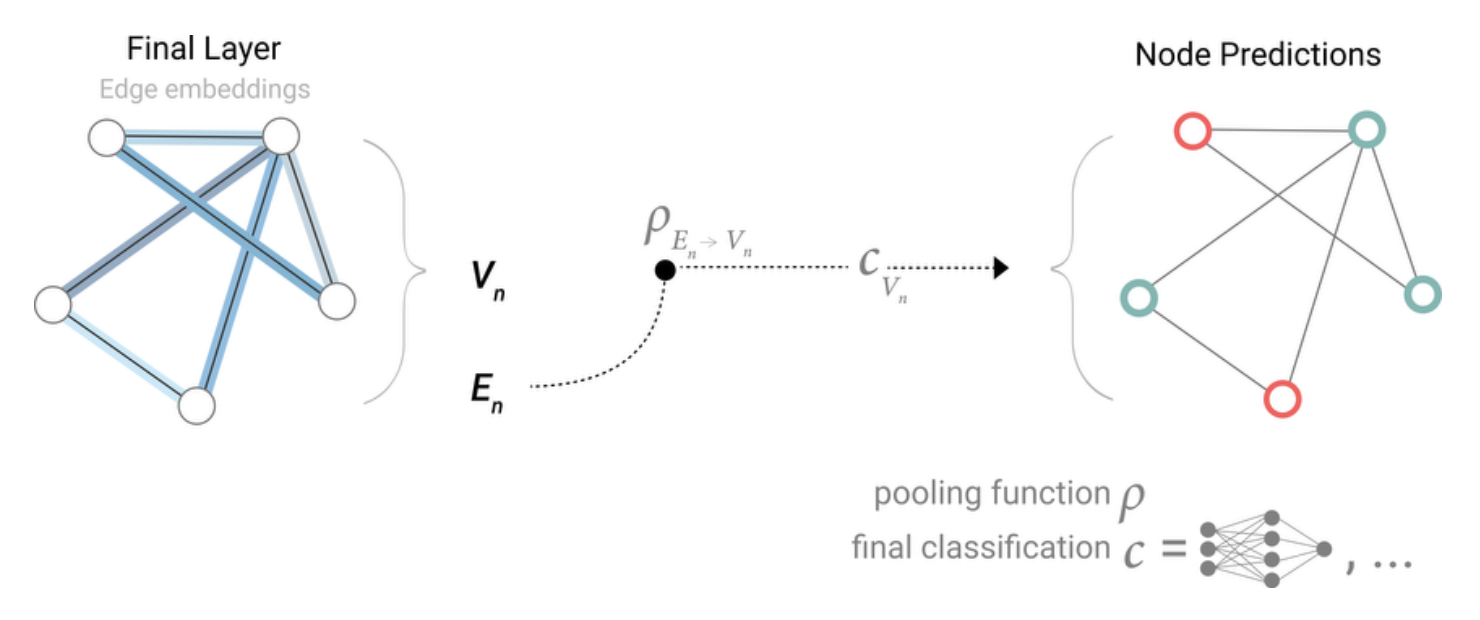
同样的,如果只有顶点向量和全局向量,则将顶点向量和全局向量汇聚到边上,然后进入边向量的输出层,最后得到边的输出。
如果没有全局向量,则可以把所有的顶点向量加起来得到一个全局向量,并进入全局的输出层得到全局的输出。
因此最简单的GNN为如下的结构:给定输入的图,进入一系列的GNN层,每个层有三个MLP对应三种不同的属性。最后输出得到保持整个图结构的输出,但里面所有的属性发生了变化,而根据要对哪个属性做预测则添加合适的输出层,如果有信息缺失的话则加入合适的汇聚层即可。这样就可以完成一个简单的预测。
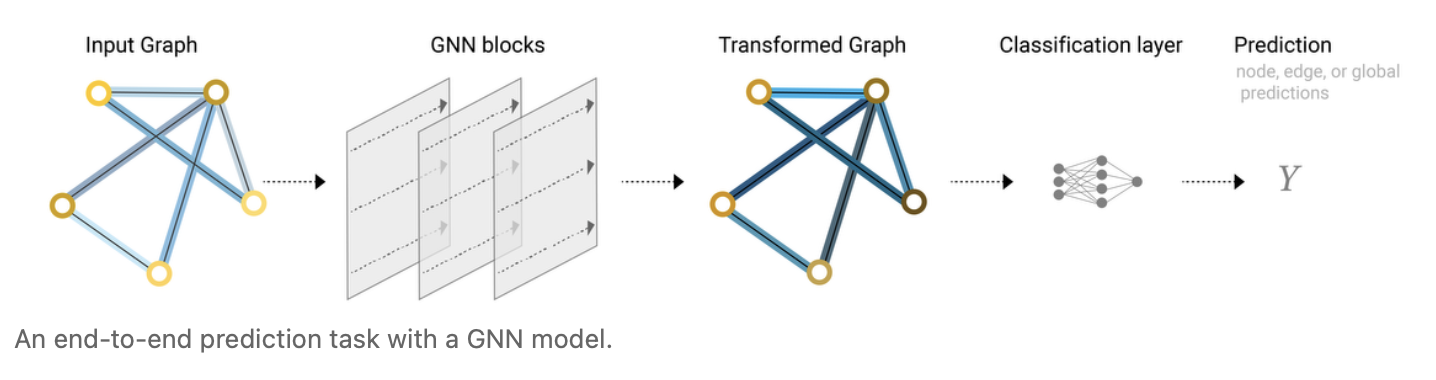
然而这种方式有所欠缺,因为将三种属性割裂开,并不能有效地融合和利用整个图的信息,顶点与边分开单独计算。因此需要一种其它方式。
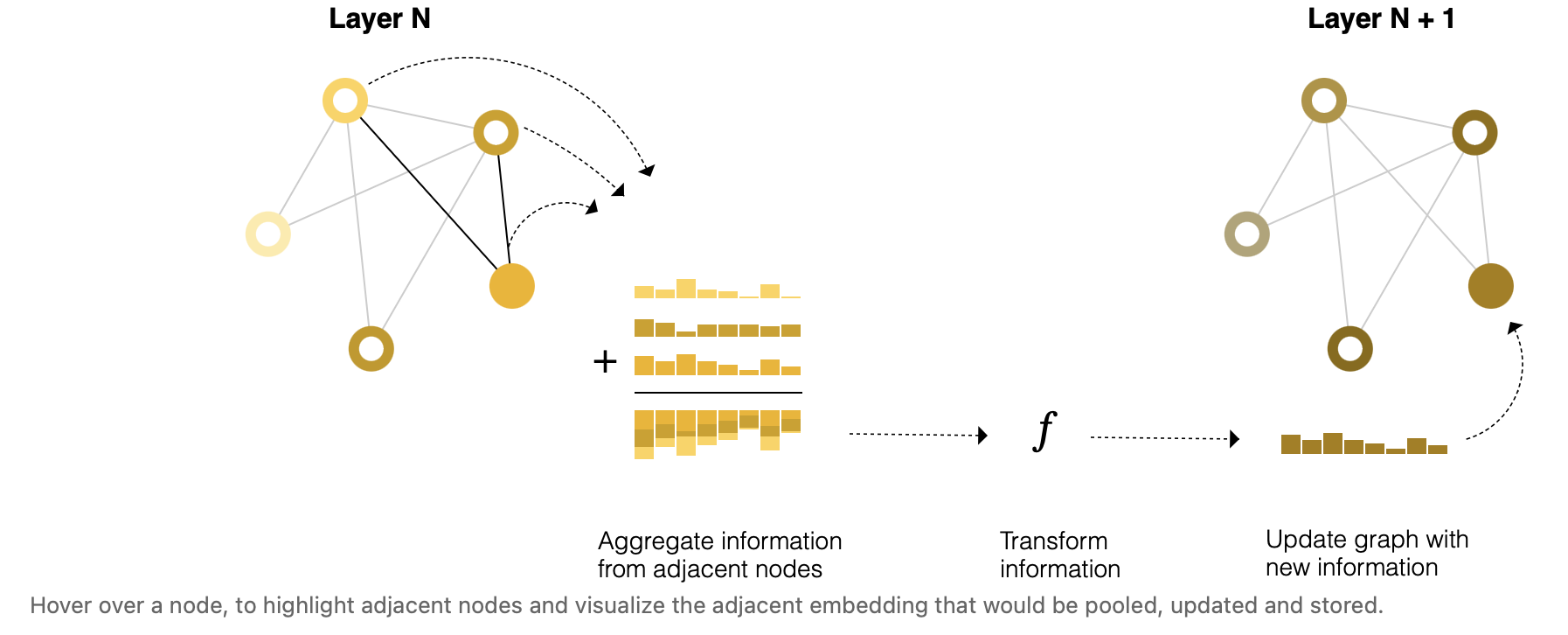
信息传递
在顶点输入MLP时,不再只是单纯输入顶点向量,而是采用将顶点向量与此顶点连接的顶点的向量相加组成的向量输入MLP进行顶点的更新,即聚合步与更新步。当叠加很多层,可以实现顶点信息长距离的传递。
其中顶点周围距离为1的邻居成为1-近邻。上述步骤即$\rho_{V_n \rightarrow V_n}$
Learning edge representation
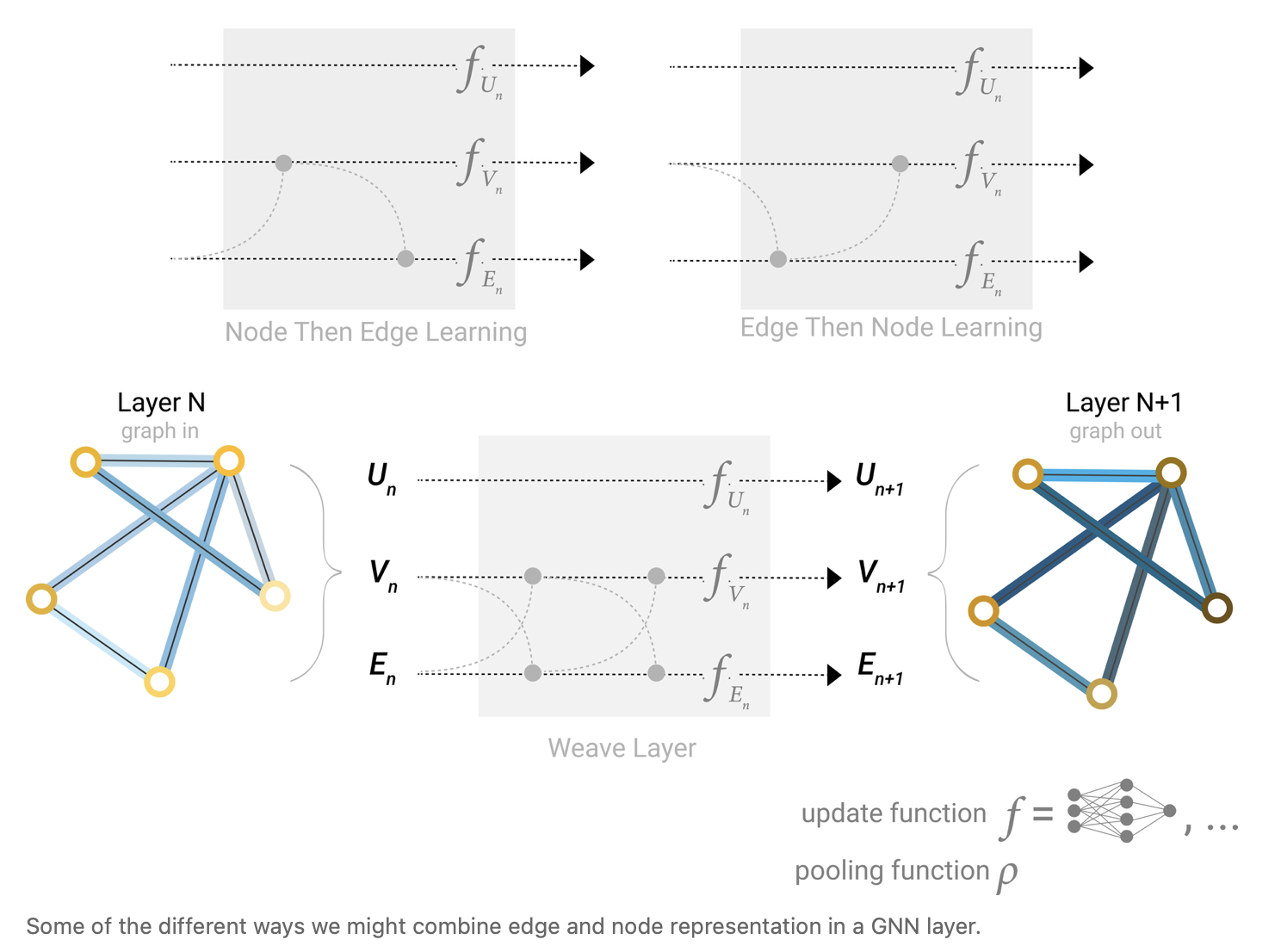
对于如何将顶点的信息传递给边,将边的信息传递给顶点,有如下的方式:
首先通过$\rho_{V_n \rightarrow E_n}$将顶点的向量传递给边,若维度不同则进行投影再传递或使用concat将两个向量并在一起。
然后再进行$\rho_{E_n \rightarrow V_n}$将边的信息再传递给顶点。
也可以反过来:
先做顶点的更新$\rho_{E_n \rightarrow V_n}$
再做边的更新$\rho_{V_n \rightarrow E_n}$
以上两种方法会出现不同的结果,且没有孰优孰劣之分。此外还可以进行交替更新。
Adding global representations
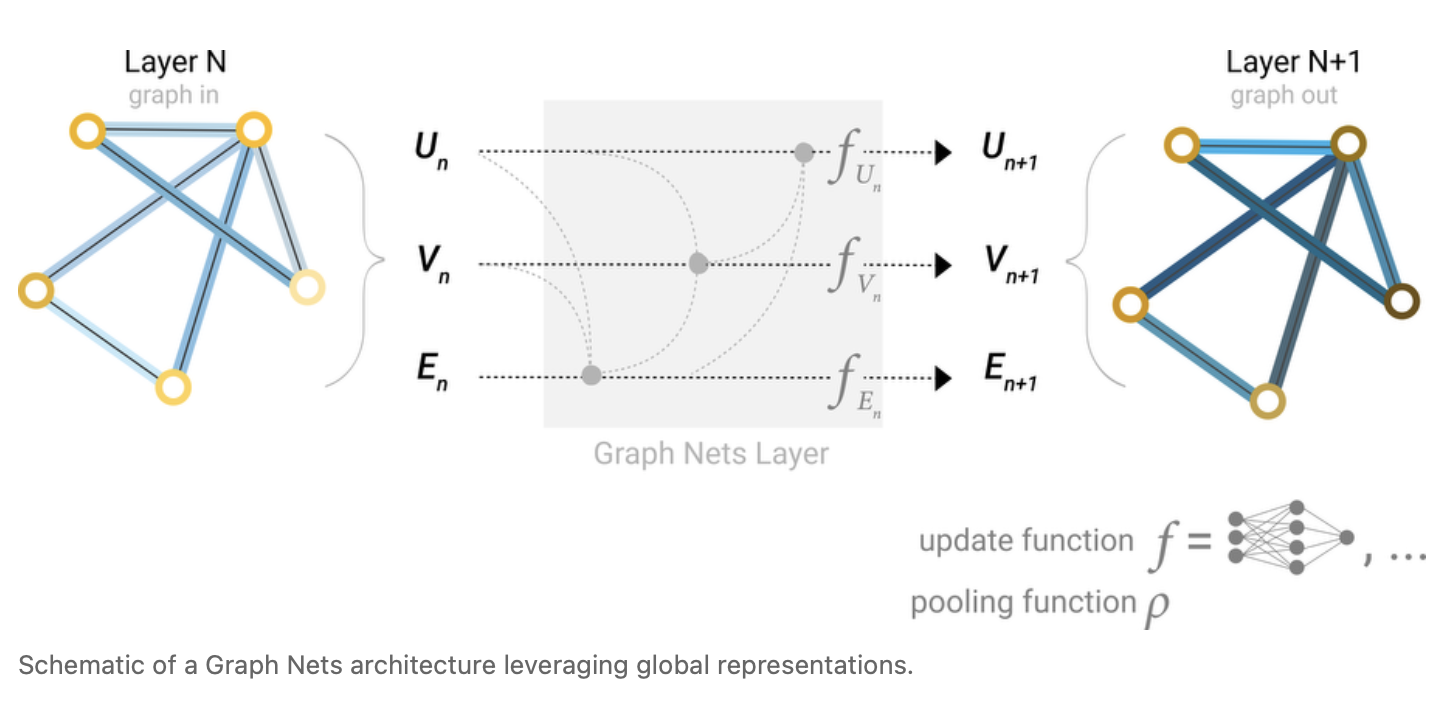
全局信息的更新
可以增加一个虚拟的顶点,称为master node或context vector,这个顶点与所有的V和E里面的内容均相连。当把顶点的信息汇聚给边的时候,会把U的信息也汇聚过来;当汇聚顶点时,也会把U汇聚过来;当汇聚U的时候,会把顶点和边的信息一起汇聚到U上,再做更新。
参数
GNN对超参数较为敏感,通常参数有四种:网络有多少层,每个属性的嵌入(embedding)维度有多高,汇聚(pooling)的操作是什么类型(最大值、均值等),怎么做信息传递(是否做信息传递,哪些属性之间做信息传递)。
相关技术
采样(batching)
如果对整个图进行计算,可能最终中间结果会非常大,因而要进行采样。常见的采样方法如下:
- 随机采样一些点,将这些点点最近的邻居找出来,在计算时在这个子图上进行计算;
- 随机游走:随机在图上找一条边,沿着这条边走到下一个节点,沿着这个图随机走,规定最多随机走多少步,从而得到一个子图;
- 结合上面两种,随机走三步,然后把这三步中的每个邻居的节点全部找出来;
- 随机选一个点,找出第1近邻,2近邻…k近邻,即做宽度遍历得到子图。
Inductive bias
此模型假设了在神经网络中保持了图的对称性。
汇聚操作的比较
汇聚操作可以求和、求平均、求最大值,然而并没有哪种特别理想。
参考文献